原文也发在知乎上。数据挖掘中常见的「异常检测」算法有哪些?
前言
我不是专业做异常检测(anomaly detection)的,但是工作有些相关,也用过一些异常检测的方法。加上今年找工作面试的时候和一个Yale小哥哥(后来知道是Yale的stat博士)友好探讨了20分钟关于无监督异常检测的问题,所以下来又看了不少资料。
这里简单说下我的经验。常见的异常检测算法其实楼上各位说得都很完备了,所以我尽量从工业界实用性的角度出发补充一些tips,大家友好交流下: )
异常检测方法
1.统计假设检验
原理
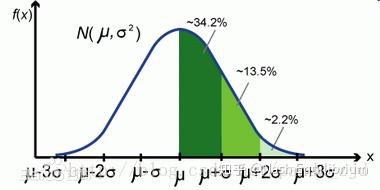
统计检验是最直观也最容易的一个方法,通常来说就是:假设原数据服从某个分布(如高斯分布),然后计算$/mu$和$/sigma$,再计算$\mu \pm 3\sigma$的区间,最后落在区间之外的数据点就被认为是异常值。暗含的思想是,落在尾部分布的数据概率很小了,几乎不可能出现;但是出现了,所以是异常的(好想吐槽……)
 一种近似的统计检验叫Grubbs Test。假设原数据服从正态分布,然后定义零假设与备择假设:
H0 :There are no outliers in the data set;
H1 :There is at least one outlier in the data set;
接下来构建Grubbs test统计量:
一种近似的统计检验叫Grubbs Test。假设原数据服从正态分布,然后定义零假设与备择假设:
H0 :There are no outliers in the data set;
H1 :There is at least one outlier in the data set;
接下来构建Grubbs test统计量:
给定显著性水平 [公式] 下,当
 时,拒绝原假设。这时候比C大的$x_{t}$中最大的那个就是异常值。然后剔除这个值,再重复计算C,直到找不出异常值或者剩下的数据量<= 6时停止。
时,拒绝原假设。这时候比C大的$x_{t}$中最大的那个就是异常值。然后剔除这个值,再重复计算C,直到找不出异常值或者剩下的数据量<= 6时停止。
适用范围
统计检验方法适用于一维数据。比如在反欺诈领域,用户支付金额、支付频次、购买特定商品次数等等,都适用于上述方法。实际上我在某团某评工作时,就用上述方法去识别了某个特定支付渠道的欺诈交易。
问题
用既有数据计算$\mu$和$\sigma$时,实际上你是把正常数据与异常数据混合计算了。对欺诈特征异常明显的数据(如下图)来说,上述方法的确有效;但当你排除了异常值或者风控上线策略规避了这些异常交易后,剩下的新数据集总是能再计算出一对新的$\mu$和$\sigma$,总是能再找到尾部分布的数值。这时候,你有足够的理由认为这些尾部分布的交易一定是异常的或者有风险的吗?
只适用于一维数据。但单纯从一维数据上进行风险判别本身就不太靠谱。用户大额支付不一定是风险,可能是买贵的商品,所以需要结合其他特征进行综合判断,统计方法就不再适用;
对于存量数据,通过统计假设检验可以一次性找出其中的高风险交易。但是对于风控从业人员来讲,业务和指标上并不允许你有足够的时间和容忍度直到高风险金额累积到显著之后再进行判别,除非你KPI不想要了: )

2.Isolation Forest
原理
周志华提出的孤立森林(isolation forest)本质上是一种无监督算法。算法原理请去看paper:
Isolation-based Anomaly Detection
sklearn集成了isolation forest模型,但官方给的例子太生硬,所以我这里用一个实际的数据集来表示无监督方法在工业界中的效果。
数据来源:Credit Card Fraud Detection
这是kaggle上的一个信用卡欺诈监测的数据集。原数据里正常交易占比99.8%,欺诈交易占比0.2%。原数据集特征经过PCA降维之后得到28维新特征,因此不用做feature engineering,直接使用isolation forest建模。
IsolationForest的一个核心参数是contamination,即异常值占比。为了展示不同异常值占比对模型性能的影响,我选取了三组不同的异常值占比:(0.01, 0.1, 0.5)。输出的混淆矩阵如下:
contamination = 0.5:
1
2
3
4
5
6
precision recall f1-score support
0 1.00 0.50 0.67 284315
1 0.00 0.97 0.01 492
avg / total 1.00 0.50 0.67 284807
contamination = 0.1:
1
2
3
4
5
6
precision recall f1-score support
0 1.00 0.90 0.95 284315
1 0.02 0.88 0.03 492
avg / total 1.00 0.90 0.95 284807
contamination = 0.01:
1
2
3
4
5
6
precision recall f1-score support
0 1.00 0.99 1.00 284315
1 0.12 0.67 0.20 492
avg / total 1.00 0.99 0.99 284807
由上可见,预设的异常值占比越接近真实占比,模型召回与F1-score越高。
问题
- 工业应用时,作为一个纯粹的无监督算法,异常值占比多少,并没有一个很好的衡量标准(拍脑袋大法好)。因此,模型上线后,仍然需要投入人力进行样本标注,才能对模型进行迭代优化。
- 特征要求高。这个例子里特征只有28个,因此模型性能好;但对于高维特征,isolation tree表现似乎一般。
3.Semi-supervised Learning
对大多数实际场景下,我们面临的既不是完全无样本标签的数据,也不是完备样本标签的数据。大多数公司一般都有一些人工标记的样本,剩下一堆无标签样本,因此半监督学习方法可能更贴近实际应用的场景。
这里举一个蚂蚁金服在今年WWW大会投中的paper的例子: Anomaly Detection with Partially Observed Anomalies
这个算法适用的场景是:仅有部分样本有标签,剩下大部分样本都无标签;异常样本的类型不止一种,往往是多种异常情形同时存在;有标签的异常样本可能并没有区分出不同的异常类型;
这个算法的主要流程分成两个阶段。在第一阶段,对已知异常样本进行聚类,并从未标记样本中挖掘潜在异常样本以及可靠正常样本;第二阶段,基于以上的样本,构建带权重的多分类模型。

问题
这个算法的假设情形很适合国内的风控业务,但我换了新公司,没数据测试哈哈哈哈所以不评论了
其他的异常检测算法
我了解的比较多的主要是时间序列的异常检测。比如Twitter开源了一个基于R的异常检测包(AnomalyDetection),原理与算法见paper: Automatic Anomaly Detection in the Cloud Via Statistical Learning
大概就是以上这些,我居然在上班时间写知乎……完了要被骂……